Nowadays the ability to extend a given product is a key feature in software industry. The same applies for products such as GWs. There could be many reasons to extend a GW such as wiretapping the message, adding your own headers or even for applying custom security policies. WSO2 GW Core is designed with this notion in mind. It is written in such a modular way so that it can be extended at several key points. In fact, you can simply go ahead and plug your own engine to the GW even when the server is up and running. In this blog post I will be explaining how easy it is to write your own engine and plug it into WSO2 GW Core.
Before we start writing the engine, let’s have a look at the key components of WSO2 GW Core and how they are connected to each other.

All right so, how does this architecture enable extensibility ? the answer to that question is explained in the next passage. We actually achieved that using OSGi declarative services. When the runtime starts Carbon Transport, it looks for a service reference of Carbon Message Processor implementation in the OSGi registry. This service reference is provided by the Carbon Message Processor bundle. Therefore, when you implement Carbon Message Processor interface, you must register its implementation as an OSGi service (you will see how it is done in the next section).
Because of this logical and physical separation of each component, we can shut down each region of the server without affecting any of the other components.
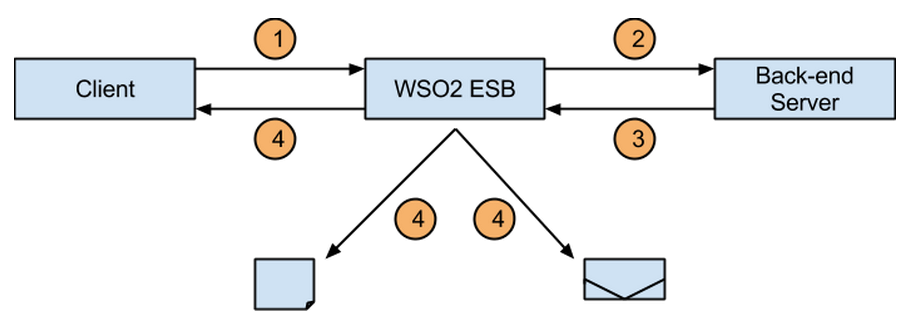
In addition to this service, there are several other OSGi services that can be used to extend the GW. I am not going into details of those as it would make this blog post too lengthy. Following diagram depicts the OSGi level interaction among each component.

White color texts represents the OSGi services that are registered by each component and the gold color text represents the services that are referenced by each component.
I think this basic background knowledge is enough to get you started. So, In this blog post we will be writing a simple Mock-Engine by extending CarbonMessageProcessor interface.
For the sake of clarity I will be explaining this in step by step manner.
Create a simple maven project. Then in the pom file there are a couple of things that we need to do. First we need to add the below dependencies to the project.
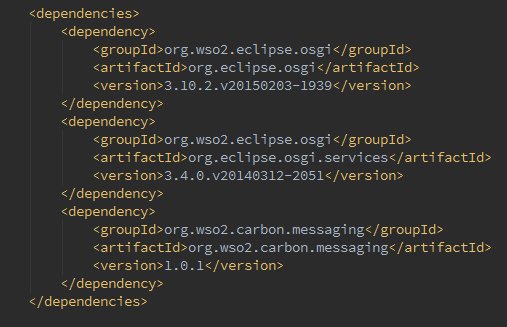
As you can see apart from OSGi dependencies all you need to add is this Carbon Messaging Dependency. In other words, the Mock-Engine is not dependending on any transport implementation.
Secondly, you need to add maven-bundle-plugin and do the necessary OSGi configurations. One thing that you need to keep in mind is apart from importing and exporting packages, it is necessary to specify the bundle activator as well. You will see why in a minute. Following is the sample configurations for maven-bundle-plugin.
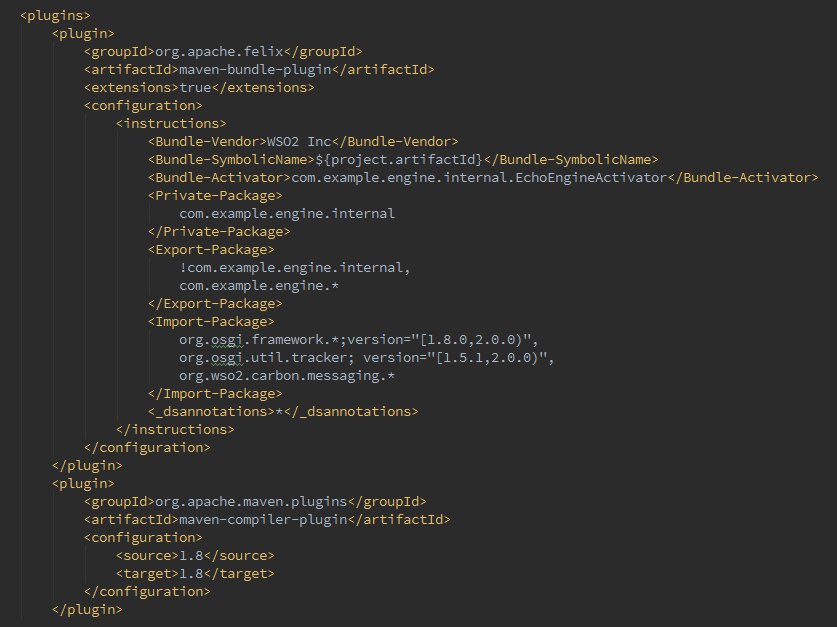
All right we are all set to move on to the second step.
Now we can start writing our Mock-Engine. First we need to create a class that extends CarbonMessageProcessor interface. When you do so, you will have to implement three key methods. I will quickly explain what each method suppose to do.
This is where the execution begins. When the Carbon Transport gets some message that message is transformed into a CarbonMessage and made available to the engine as a parameter of this method. Usually, a CarbonMessage includes a header section, a body section and a properties section.
Then in order to send back a response to the client we can use the CarbonCallback.
Eeven though this method is not implemented in this example. The responsibility of this method is to provide a sender to the engine. So that the engine can send messages to the back-end and get responses.
This method is simply used to provide a name for this engine. This name will be used internally to add and remove the engine dynamically from the runtime.
Now that you have some idea on CarbonMessaegProcessor interface, let’s see how it is implemented in the Mock-Engine.
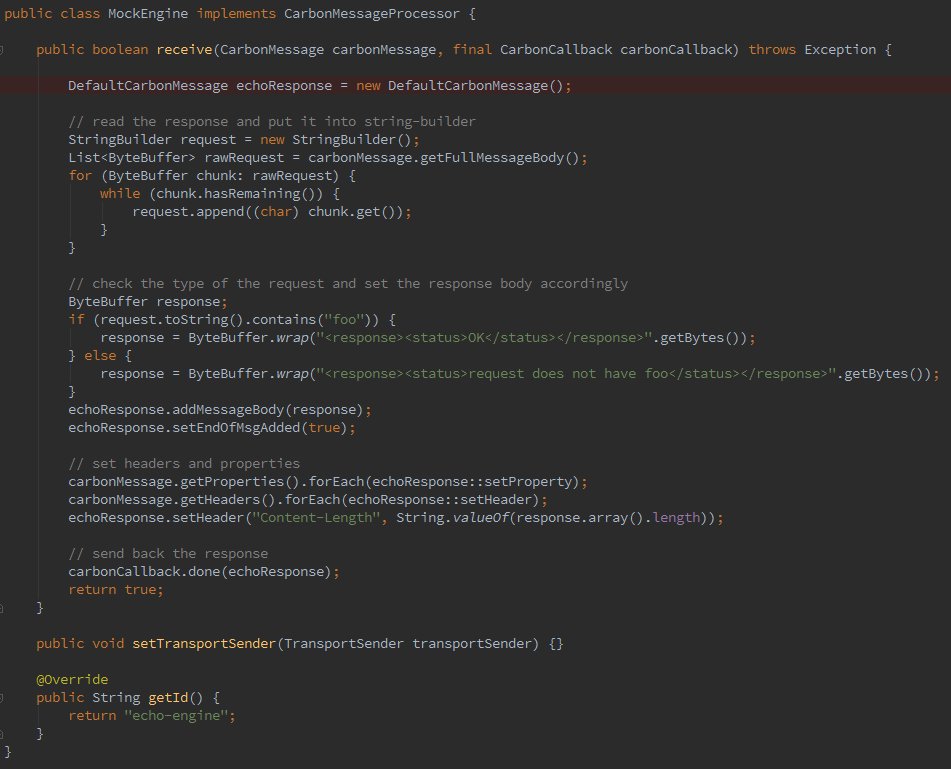
As you can see, it is very straight forward. It simply reads the content of the request CarbonMessage into a StringBuilder. Then based on the request content, it sends back the response using a new CarbonMessage. In this case, we simply check for foo in the request and send back the response accordingly. But you can implement any logic here. This was done simply for demonstration purposes.
Once you have extended the CarbonMessagProcessor, there is only one last thing to do and that is to implement the bundle activator.
In the OSGi bundle activator, we simply register this newly created engine as an OSGi service. This enables us to dynamically add and remove the engine from the runtime without restarting the GW. Following is the code you need to add.
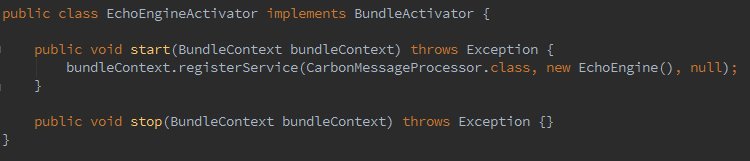
That is it. Once you’ve put those pieces together, you can simply go ahead and build the project that will result in creating the Mock-Engine as an OSGi bundle. Now let’s try out the new engine.
Download the latest GW release from here. Start the GW in OSGi console mode. In order to do that find launch.properties and uncomment osgi.console= line. Afterwards, use carbon.sh to start the server.
Once the server is successfully started. Use the below command to install the new engine.
Upon successful installation, you should be able to see something like in the below image.

Now you can start the bundle with the below command.
osgi> start 48
Then using the stop command, we can stop the default engine as follows.
osgi> stop 36
That is it. You have successfully installed the new engine to the runtime. Now let’s send a request and see. Use the below command to try-out the new engine and you should get a 200 OK response.
I hope this blog post helps you understand and get started with writing GW engines. I also want to thank Kasun and Senduran for helping me out with this blog.
Before we start writing the engine, let’s have a look at the key components of WSO2 GW Core and how they are connected to each other.
High Level Architecture

As you can see there are three main components and these components are organized in such a way so that we can separate the transport implementations from engine implementations. Each component’s responsibilities are as follows,
- Carbon Transport component provides the transport implementation of the GW.
- Carbon Messaging component provides the messaging capability to GW. Each component talks to each other using CarbonMessages that are provided by Carbon Messaging component.
- Carbon Message Processor provides whatever the required business logic implementation to GW such as header based routing, content based routing, etc.
OSGi Level Interaction
All right so, how does this architecture enable extensibility ? the answer to that question is explained in the next passage. We actually achieved that using OSGi declarative services. When the runtime starts Carbon Transport, it looks for a service reference of Carbon Message Processor implementation in the OSGi registry. This service reference is provided by the Carbon Message Processor bundle. Therefore, when you implement Carbon Message Processor interface, you must register its implementation as an OSGi service (you will see how it is done in the next section).
Because of this logical and physical separation of each component, we can shut down each region of the server without affecting any of the other components.
In addition to this service, there are several other OSGi services that can be used to extend the GW. I am not going into details of those as it would make this blog post too lengthy. Following diagram depicts the OSGi level interaction among each component.

I think this basic background knowledge is enough to get you started. So, In this blog post we will be writing a simple Mock-Engine by extending CarbonMessageProcessor interface.
Writing a Simple Mock-Engine
For the sake of clarity I will be explaining this in step by step manner.
Step 1
Create a simple maven project. Then in the pom file there are a couple of things that we need to do. First we need to add the below dependencies to the project.
As you can see apart from OSGi dependencies all you need to add is this Carbon Messaging Dependency. In other words, the Mock-Engine is not dependending on any transport implementation.
Secondly, you need to add maven-bundle-plugin and do the necessary OSGi configurations. One thing that you need to keep in mind is apart from importing and exporting packages, it is necessary to specify the bundle activator as well. You will see why in a minute. Following is the sample configurations for maven-bundle-plugin.
All right we are all set to move on to the second step.
Step 2
Now we can start writing our Mock-Engine. First we need to create a class that extends CarbonMessageProcessor interface. When you do so, you will have to implement three key methods. I will quickly explain what each method suppose to do.
public boolean receive(CarbonMessage carbonMessage, final CarbonCallback carbonCallback)
This is where the execution begins. When the Carbon Transport gets some message that message is transformed into a CarbonMessage and made available to the engine as a parameter of this method. Usually, a CarbonMessage includes a header section, a body section and a properties section.
Then in order to send back a response to the client we can use the CarbonCallback.
public void setTransportSender(TransportSender transportSender)
Eeven though this method is not implemented in this example. The responsibility of this method is to provide a sender to the engine. So that the engine can send messages to the back-end and get responses.
public String getId()
This method is simply used to provide a name for this engine. This name will be used internally to add and remove the engine dynamically from the runtime.
Now that you have some idea on CarbonMessaegProcessor interface, let’s see how it is implemented in the Mock-Engine.
As you can see, it is very straight forward. It simply reads the content of the request CarbonMessage into a StringBuilder. Then based on the request content, it sends back the response using a new CarbonMessage. In this case, we simply check for foo in the request and send back the response accordingly. But you can implement any logic here. This was done simply for demonstration purposes.
Once you have extended the CarbonMessagProcessor, there is only one last thing to do and that is to implement the bundle activator.
Step 3
In the OSGi bundle activator, we simply register this newly created engine as an OSGi service. This enables us to dynamically add and remove the engine from the runtime without restarting the GW. Following is the code you need to add.
That is it. Once you’ve put those pieces together, you can simply go ahead and build the project that will result in creating the Mock-Engine as an OSGi bundle. Now let’s try out the new engine.
Trying out The Engine
Download the latest GW release from here. Start the GW in OSGi console mode. In order to do that find launch.properties and uncomment osgi.console= line. Afterwards, use carbon.sh to start the server.
Once the server is successfully started. Use the below command to install the new engine.
osgi> install file:/media/shafreen/source/echo-engine/target/mock-engine-1.0.0.jar
Upon successful installation, you should be able to see something like in the below image.

osgi> start 48
Then using the stop command, we can stop the default engine as follows.
osgi> stop 36
That is it. You have successfully installed the new engine to the runtime. Now let’s send a request and see. Use the below command to try-out the new engine and you should get a 200 OK response.
curl -v localhost:9090 -H "Content-Type: application/xml" -d "<test/>foo</test>"
I hope this blog post helps you understand and get started with writing GW engines. I also want to thank Kasun and Senduran for helping me out with this blog.
.png)



.png)






.png)

