Introduction
While we were at customer site, we were bombarded with above subject. We almost chocked ourselves answering those questions. So, I though of writing a blog post based on the experience and the knowledge I gained during my on-site engagement. This blog post explains everything you need to know about Hazelcast clustering in a production deployment.
Why do we need clustering
In a typical enterprise deployment we don't deploy a single instance of a given server as it could result in a single point of failure i.e if the deployed server goes down the complete system will be unusable. Thus we always tend to deploy multiple instances of a given server in order to increase the Availability of a system.
However, this is only one aspect of this. The other aspect of this is Scalability of a given deployment. In modern enterprise systems a single server instance is not enough to cater the number of incoming request. Therefore, in order to scale we always add more instances to the existing system. This is called Horizontal scaling. Though we could also upgrade server specs such as increasing the memory and CPU speed in order to scale (which we call vertical scaling), there is always a limit and whether we like it or not we have to add more instances to scale.
So it is obvious that we need to have multiple instances of a given server in an enterprise deployment. Needless to say adding more instances adds more complexity to the system. In order to be consistent regardless of numbers servers you've added, you may have to replicate the state and make servers communicate with each other and that is where clustering comes to picture.
So it is obvious that we need to have multiple instances of a given server in an enterprise deployment. Needless to say adding more instances adds more complexity to the system. In order to be consistent regardless of numbers servers you've added, you may have to replicate the state and make servers communicate with each other and that is where clustering comes to picture.
Clustering Concepts
Membership discovery phase
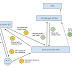
When you add a new node to an existing system, it has to convert itself to a member of the existing cluster. A member of a cluster knows about each other in the cluster, which allows that member to change its state to match with other core-existing members. There are two mechanisms to become a member of a cluster. A node can either use Well Known Address (WKA) mechanism or Multicast mechanism. Now what are these ?
Multicast mechanism
In Multicast a node advertises its details to others using a multicast channel. All the other members get to know about the new node through this multicast channel, which allows them to start communicating with the new node. This allows the node to a become member in the cluster. However, Multicast is not preferred for production deployments as it could add an unnecessary overhead to the network. As a result, it is more often use for testing purposes.

Well Known Address (WKA) mechanism
In WKA there is a set o well known members and everybody knows about these members. When a node wants to become a member of the cluster, it connects to one of the well known members and declare its details. Then the well known member provides all the information about the cluster and let every member in the cluster know about the new node. This allows the node to become a member of the cluster. This is the widely used membership discovery mechanism in clustering.

Static vs Dynamic membership
A cluster deployment could have static, dynamic or hybrid members. In a static clustered setup there is a fix set of members and it is not possible to add a new member to the cluster without restarting the system. IP address and port number of static members are predefined. In a Dynamic clustered setup we can always add new members to the system without restarting. However, in Hazelcast we always use a hybrid clustered setup where we have both static and dynamic set of members. Static members are the well known members who have a predefined IP and port.
Member's view
Each member in the cluster has its own view of the cluster. Once it discovers the members of a cluster it keeps track of these members. Normally, this is done by maintaining a heart-beat pulse between other members. This way when a member goes down it could detect it and remove that member from the healthy list. However, this is also called unreliable failure detection as members may not respond to the heart-beat request due to the load on that member and not because it is really down.
Clustering domains
This may not come under general clustering concepts but rather specific to WSO2. In order to identify a cluster we label it with a domain name. Clustering messages will only be sent to the members of that particular domain. In addition to that, this way we can route the traffic only to the relevant set of instances. For example, let's say there is a load balancer fronted with multiple cluster domains of ESB and BPS. Load balancer will look into the domain mapping and route the message to the specific cluster domain. Therefore, ESB requests are isolated from BPS requests and vise versa.
Now that you have a basic idea about the concepts of clustering, in part 2 I'll be discussing how to configure WSO2 carbon servers using Hazelcast.


.png)


0 comments :
Post a Comment